
AWS EC2 서버 터짐… (서버 재부팅, 경보 설정)
AWS 카테고리의 다른 글
밤사이 저의 AWS EC2 서버가 터졌습니다. 아쉽게도 사용자가 많아 터진 것은 아니었습니다… ㅎ
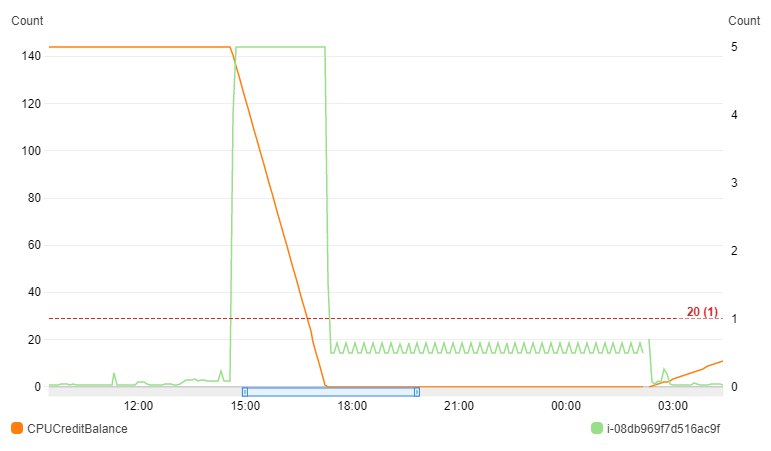
그래프에서 초록색 선이 CPU 사용량(CPU Utilization)이고, 주황색 선이 보유 크레딧 개수(CPU Credit Balance) 입니다. 태평양표준시(UTC) 기준 15시부터 18시 사이에 CPU 사용량이 100%로 유지되었고, 그 이후 크레딧이 모두 소진되어 10%의 사용량이 유지되었습니다.(크레딧을 소진하지 않는 최대 사용량이 10%인 것 같습니다) 그리고 다음날 3시쯤, 제가 이 사실을 발견하고 서버를 재부팅하여 다시 CPU 사용량이 줄어들고 크레딧이 늘어나기 시작했습니다.
서버 재부팅
서버가 터진 사실을 발견했을 당시, AWS EC2 서버가 풀가동되고 있는 상태였기 때문에 AWS Console에서 EC2 인스턴스에 연결할 수 없었습니다. 그래서 어떤 작업이 CPU를 사용하고 있는지 모니터링할 수 없었고, 서버를 재부팅해야했습니다. AWS Console의 EC2 관리 페이지에서 재부팅을 쉽게 할 수 있습니다.
원인파악
당시에 앵무새봇은 작동하지 않는 상태였고, LoLog.me 페이지는 정상적으로 작동하고 있었습니다. 또한 앵무새봇의 로그에서 음악을 재생한 로그는 찍혔지만 음악이 끝난 로그는 찍히지 않았고, 그 시점이 서버가 과부하된 시점과 일치했기에 앵무새봇의 문제라고 판단했습니다. 아마 유튜브로 음악을 스트리밍해주는데 사용한 ytdl-core-discord 모듈의 버그로 보입니다.
AWS CloudWatch 경보 설정 (Alert)
정확한 원인을 찾고 이를 해결하지는 못했지만, 다시 비슷한 문제가 발생했을 때, 서비스가 몇시간동안 중지되고 이를 제가 파악하지 못하는 일이 반복되지 않도록 AWS CloudWatch의 경보 기능을 활성화시켰습니다.
AWS Console에서 CloudWatch -> 경보 탭에 들어가면 경보를 생성할 수 있습니다. EC2 뿐만 아니라 RDS나 다른 AWS 서버들의 모니터링 지표를 기준으로, 기준치가 초과되었을 경우 메일을 보내주거나 간단한 작업을 수행시킬 수 있습니다.
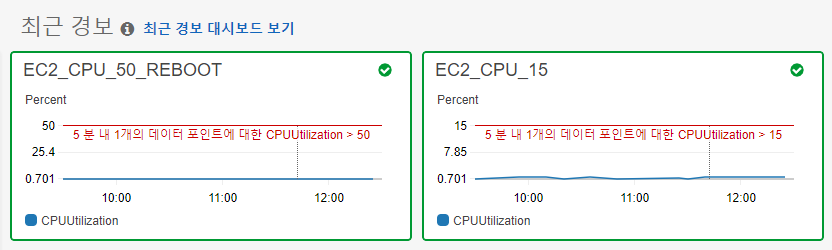
저는 CPU 사용량이 15%가 넘을 경우 저에게 메일이 발송되도록 설정했고, 50%를 초과할 경우에는 서버가 자동으로 재부팅되도록 설정했습니다.
이제 동일한 문제가 발생했을 때에, 상황을 빠르게 인지하고 서버가 오랜 시간 동안 과부하되는 일을 방지할 수 있게 되었습니다.
추가로 해야할 일
-
정확한 원인을 파악하고 코드를 수정할 것(ytdl-core-discord 모듈의 문제라면, GitHub에 이슈를 띄울 것)
-
서버가 자동으로 재부팅되면 실행되던 앱들이 종료되므로, 자동으로 앱을 실행시키는 방법을 찾을 것
댓글남기기