
Node.js로 네이버 크롤링하기(맛보기)
Node.js 카테고리의 다른 글
Node.js를 이용하면 웹 크롤링을 간편하게 해볼 수 있습니다.
저는 crawler모듈을 사용하여 네이버 홈페이지를 크롤링해보겠습니다.
목표
네이버 메인페이지에서 언론사 리스트를 가져와 출력해보고자 합니다.

Crawler 모듈 설치
모듈의 사용법은 모듈이 업데이트됨에 따라 달라질 수 있으므로,
공식문서를 참고하시는 것을 추천드립니다.
아래의 명렁어를 통해 crawler 모듈을 설치할 수 있습니다.
npm install crawler --save
공식 문서에 나와있는 기본 사용법 중에서
아래의 코드를 그대로 복사해서 이용해 보겠습니다. (주석 참조)
var Crawler = require("crawler");
var c = new Crawler({
maxConnections : 10,
// This will be called for each crawled page
callback : function (error, res, done) {
if(error){
console.log(error);
}else{
var $ = res.$;
// $ is Cheerio by default
//a lean implementation of core jQuery designed specifically for the server
console.log($("title").text());
/***************************************************
이부분에서 jQuery를 이용해 데이터를 파싱하고 출력할 것입니다.
****************************************************/
}
done();
}
});
// Queue just one URL, with default callback
c.queue('http://www.naver.com');
// url은 네이버의 주소로 변경해줍니다.
이 코드는 title정보를 출력하는 코드이기 때문에
실행하면 NAVER가 출력됩니다.
코드를 수정하여 언론사 목록을 출력해봅시다!
크롤링 타겟 파악
웹페이지의 크롤링하고자 하는 부분에서
마우스 우클릭 > 검사를 눌러줍니다.(크롬 브라우저 기준)
저는 네이버 메인페이지에서 언론사 리스트를 가져오고 싶으므로
밑의 이미지와 같은 위치에서 검사를 해주었습니다.
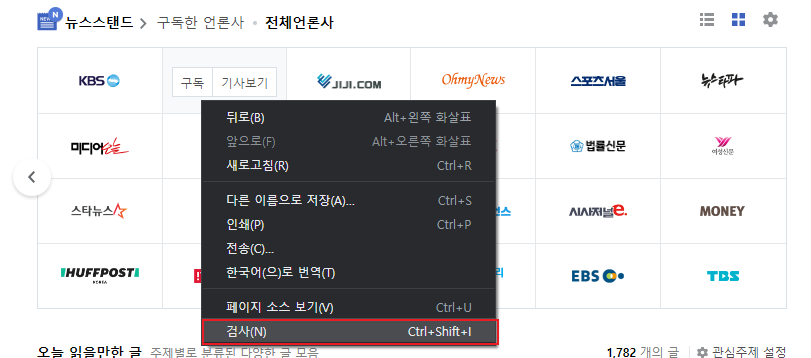
html코드 위에서 마우스를 움직이면서 타겟이 어떤 태그 안에 있는지 찾아줍니다.

언론사의 리스트는 "thumb_area"의 클래스 이름을 가진 div태그 안에 있었습니다.
각각의 언론사는 "thumb_box"의 클래스 이름을 가진 div태그안에 있었습니다.
jQuery로 데이터 파싱
crwaler 모듈의 베이스 코드를 보면,
jQuery를 사용할 수 있도록 변수 $가 정의되어 있습니다.
jQuery를 사용해 원하는 부분을 $bodyList에 저장해줍니다.
const $bodyList = $("div.thumb_area").children("div.thumb_box");
제가 찾는 언론사의 이름 정보는
a 태그 내부의 img태그의 alt 속성에 정의되어 있었습니다.

역시나 jQuery를 이용하여 원하는 정보를 추출해 줍니다.
let newsList = [];
$bodyList.each(function(i, elem) {
newsList[i] = $(this).find('a.thumb img').attr('alt');
});
결과
콘솔에 결과를 출력해 줍니다.
console.log(newsList);

성공!
완성된 코드 GitHub
var Crawler = require("crawler");
var c = new Crawler({
maxConnections : 10,
// This will be called for each crawled page
callback : function (error, res, done) {
if(error){
console.log(error);
}else{
var $ = res.$;
// $ is Cheerio by default
//a lean implementation of core jQuery designed specifically for the server
console.log($("title").text());
const $bodyList = $("div.thumb_area").children("div.thumb_box");
let newsList = [];
$bodyList.each(function(i, elem) {
newsList[i] = $(this).find('a.thumb img').attr('alt');
});
console.log(newsList);
}
done();
}
});
// Queue just one URL, with default callback
c.queue('http://www.naver.com');
댓글남기기